Learning Control
Iterative Learning Control

A Classic Iterative Learning Control Scheme
To compensate for the reality gap, we implemented different Iterative Learning Control (ILC) algorithm.
Repetion after repetion of a fixed trajectory, the iterative controller update its action until a minimazion of the tracking error is achieved.
ILC has serval properties worth mentioning:
- Mostly works in a feedforward fashion being able to preserve the elasticty of the robot.
- Can exploit model-based initial guess or terms in the controller itself to speed up the learning process.
- Compensate for the underactuation of the robot.
- Use real data for the learning process implementing a learning-while-doing paradigm.
- Thoeretical guarantee for the convergence of the tracking error via sufficcient conditions.
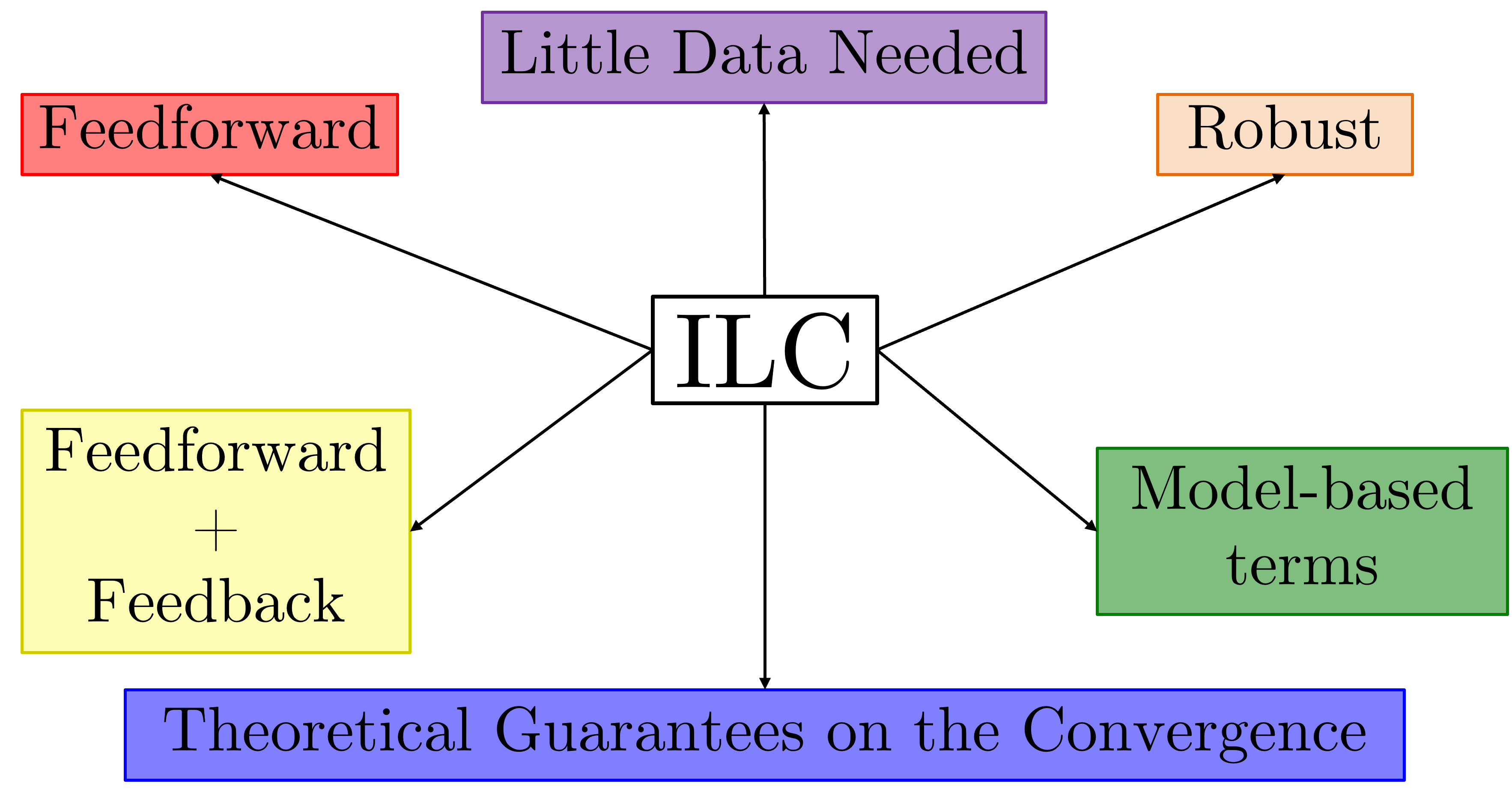
A Properties of the Iterative Learning Control Framework
We publish the following papers:
- Iterative Learning Control for Compliant Underactuated Robots 2023 (IEEE TSMC:S).
- A Provably Stable Iterative Learning Control for continuum Soft Robots 2023 (IEEE RA-L).
- Swing-up of Underactuated Compliant arms via Iterative Learning Control 2022 (IEEE RA-L).
- A Robust Iterative Learning Control for Continuous-time Nonlinear Systems with Disturbances 2021 (IEEE Access).
- Trajectory Tracking of a One-Link Flexible arm via Iterative Learning Control 2020 (IEEE IROS).
VSA 4 DoFs Swing \(j=0\)
VSA 4 DoFs Swing \(j=10\)
VSA 4 DoFs Swing-Up \(j=10\)
Neck-like Soft Continous Robot \(j=6\)
Combining ILC with Reinforcement Learning
R-ILC Scheme combining ILC and RL
This combined framework tries to combine the best features of both the controllers:
- Feedforward and feedback actions for preserving the elasticty and incresing the robustness of the controller.
- Sampling quality data for the traning.
- Use real data for the testing process implementing a learning-while-doing paradigm.
- Thoeretical guarantee for the convergence of the tracking error via sufficcient conditions.
Learning process of ILC
Learning process of R-ILC
Locomotion with Reinforcement Learning
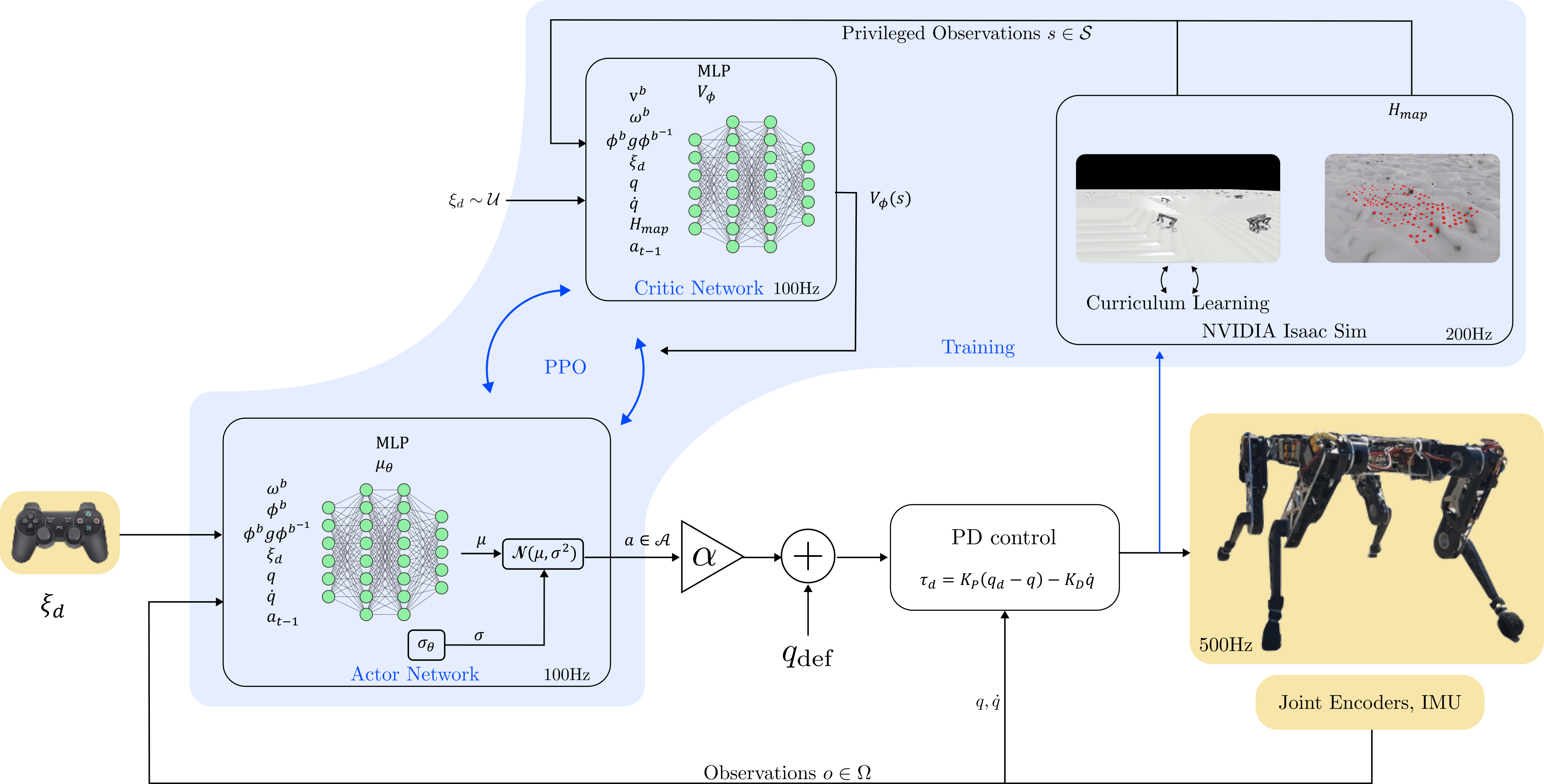
RL control for Otto's locomotion
Our RL locomotion control optimizes policies in simulation, allowing stable and efficient movement despite Otto being an 8-DoF quadrupedal robot.
Through extensive simulation training, leveraging highly parallel GPU-accelerated simulators, we ensure the policy is well-suited for deployment in real-world scenarios.